Move over AlphaGo: AlphaZero taught itself to play three different games
Por um escritor misterioso
Descrição
DeepMind's new AI is worthy successor to the first program to beat a human at Go.
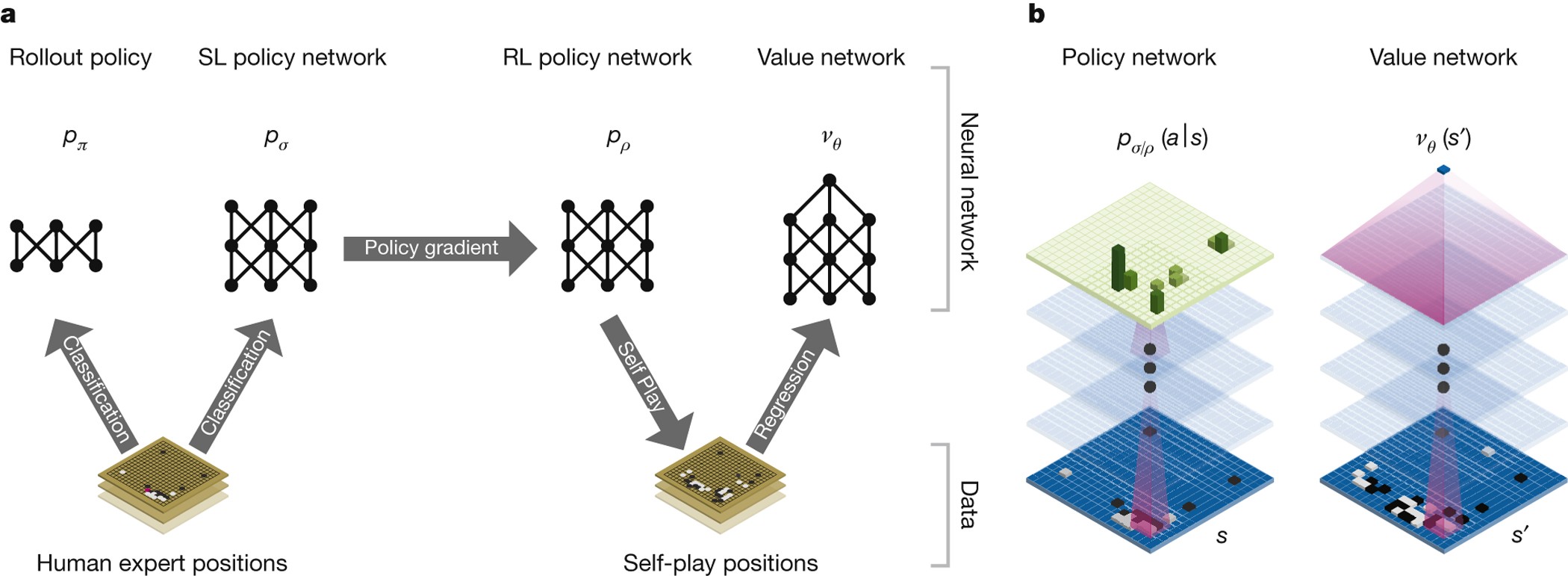
Mastering the game of Go with deep neural networks and tree search

Why DeepMind AlphaGo Zero is a game changer for AI research
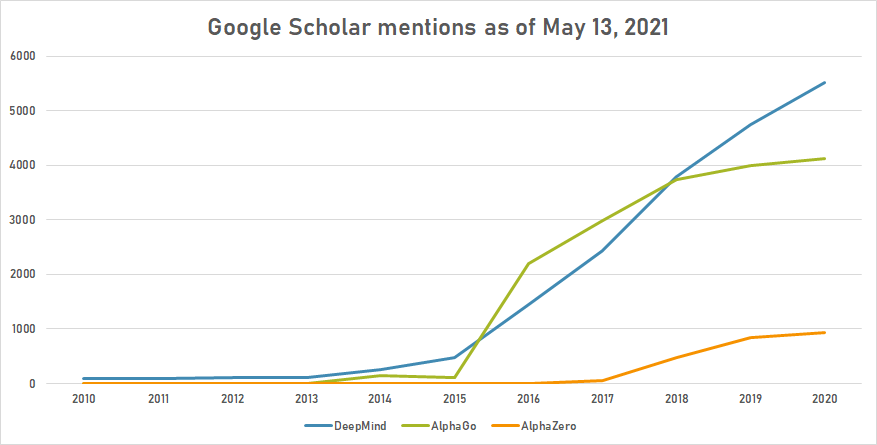
Timeline of AlphaGo - Timelines
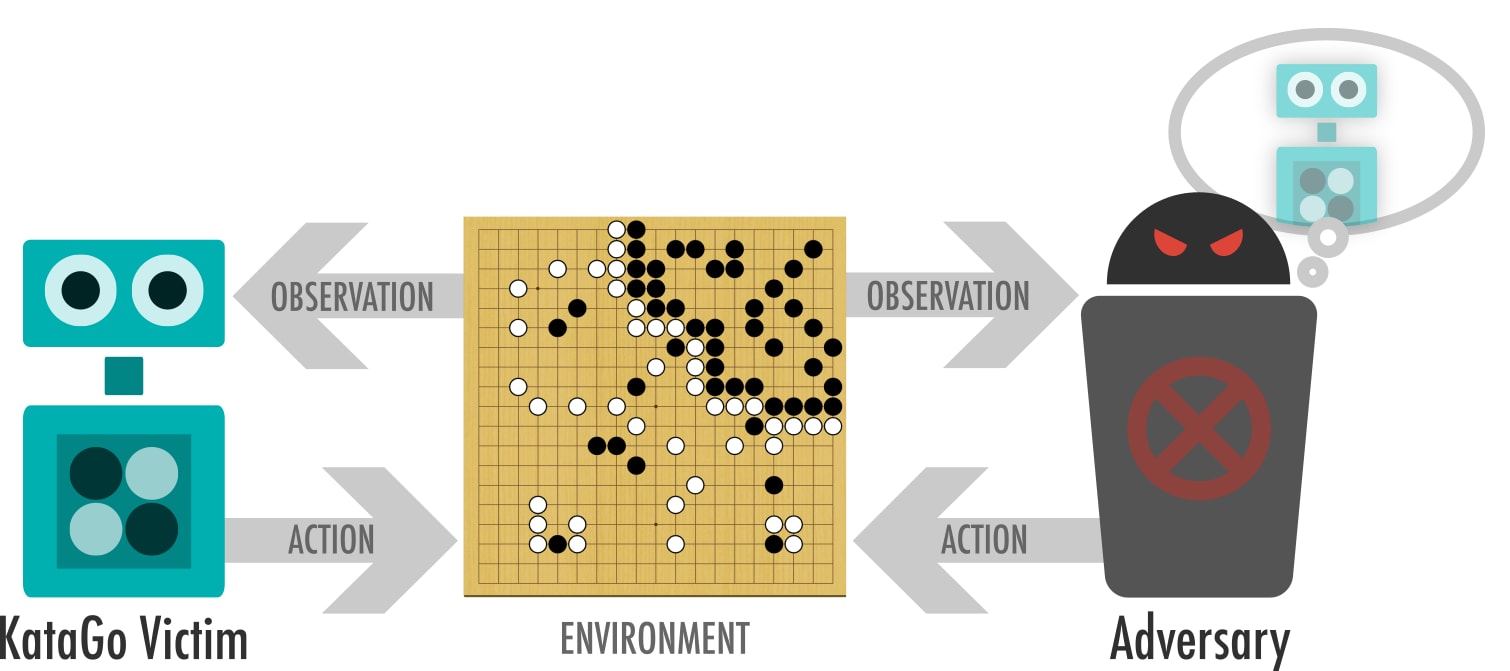
Even Superhuman Go AIs Have Surprising Failure Modes — LessWrong
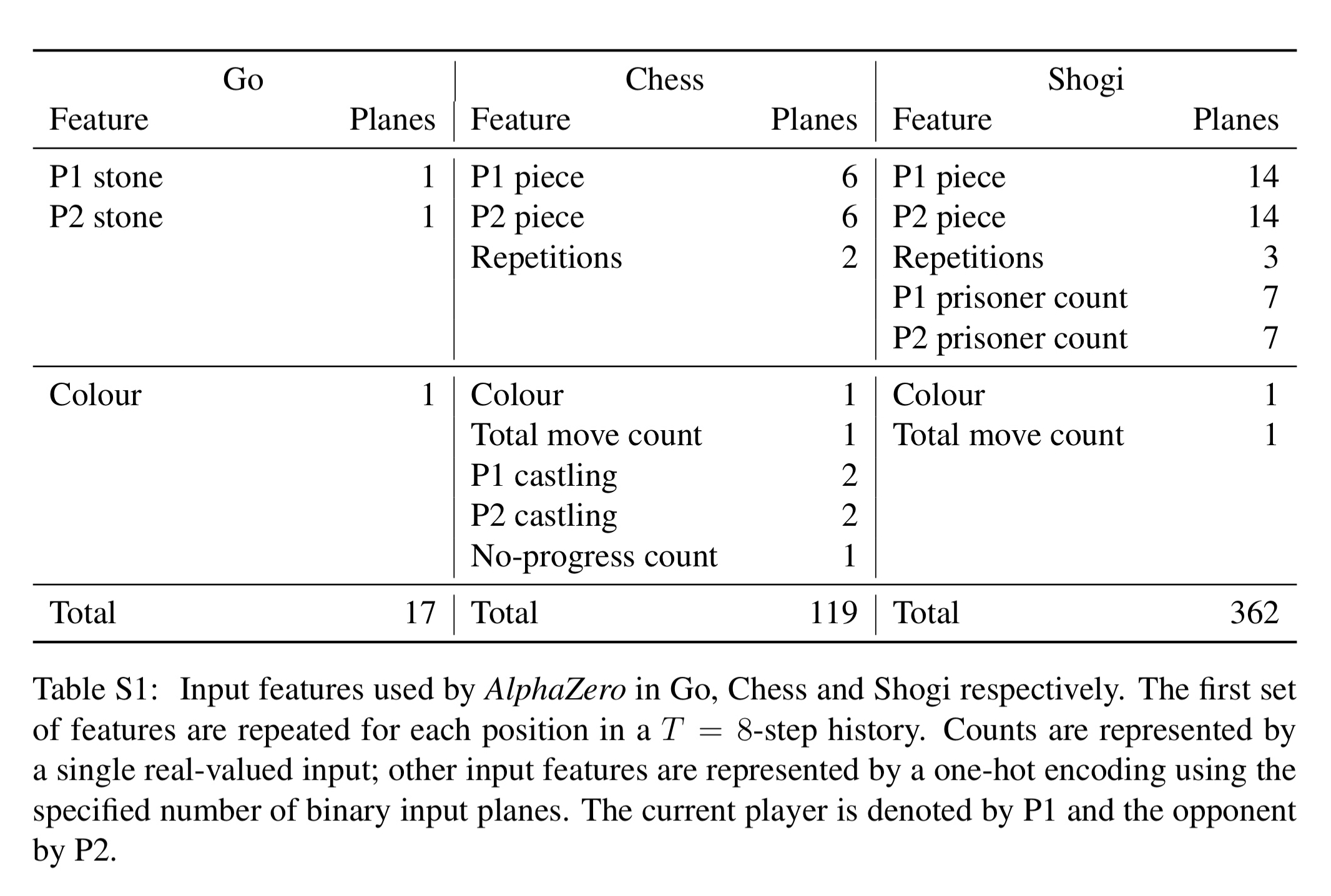
Mastering chess and shogi by self-play with a general reinforcement learning algorithm

DeepMind's Go playing software can now beat you at two more games
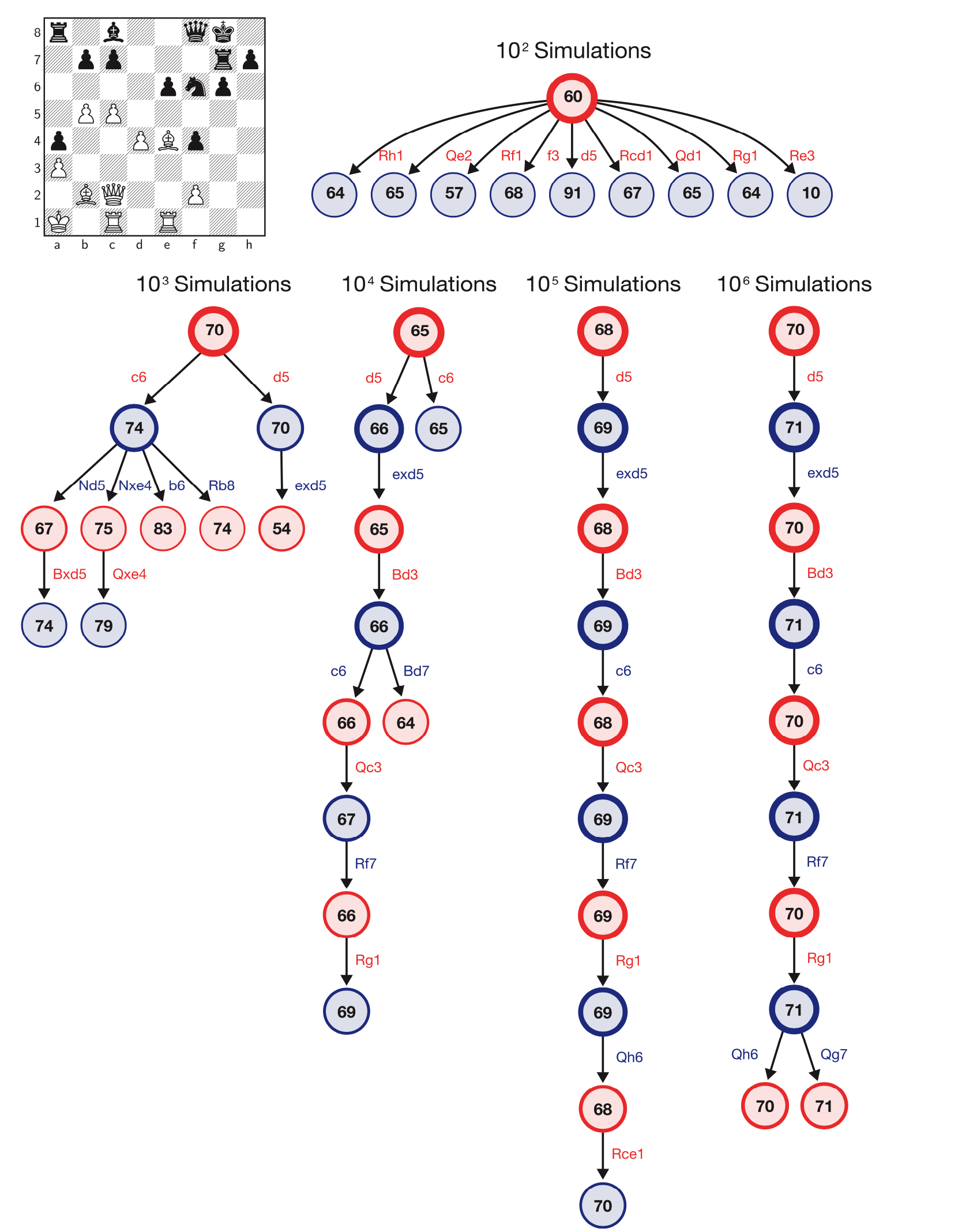
AlphaZero Crushes Stockfish In New 1,000-Game Match
Is there an Open Source version of AlphaZero? (specifically, the generic game-learning tool, distinct from AlphaGo) - Quora

Checkmate: how we mastered the AlphaZero cover, Science
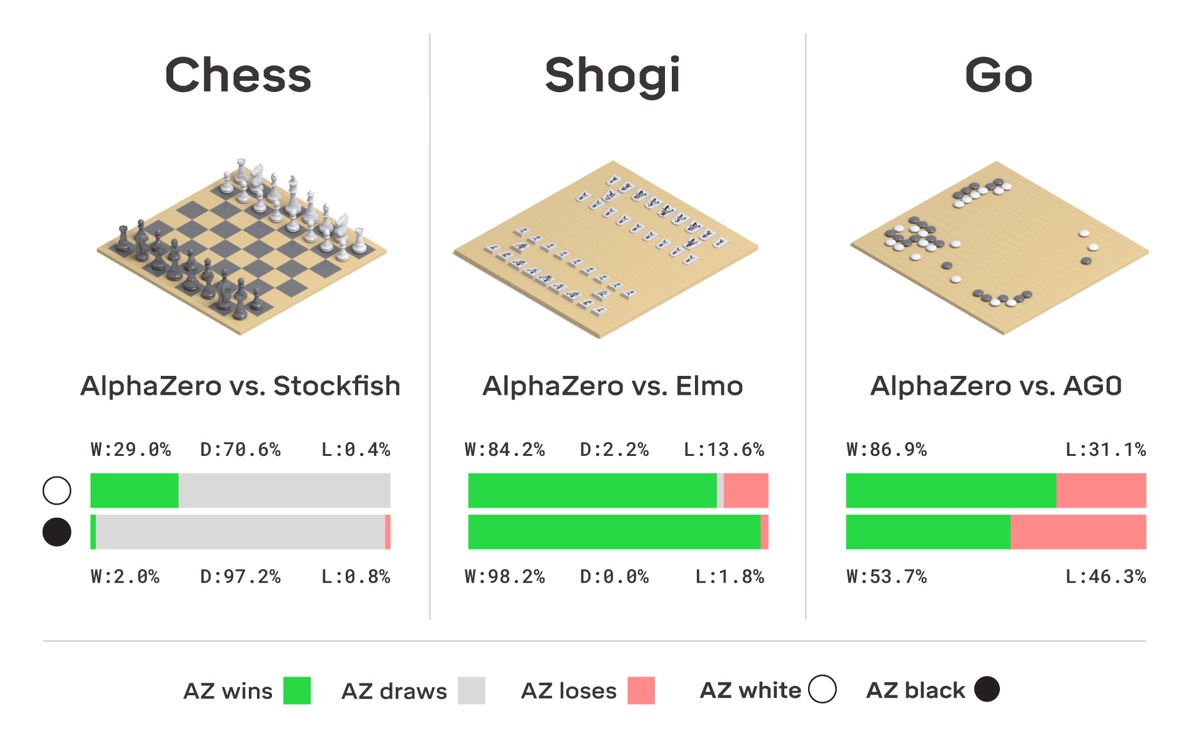
Move over AlphaGo: AlphaZero taught itself to play three different games
de
por adulto (o preço varia de acordo com o tamanho do grupo)